Using RSelenium to scrape a paginated HTML table
Trying to answer this question on stackoverflow about understat.com scraping I was interested to take RSelenium for a spin.
Few years ago, Selenium and R weren’t particularly friends (Python+Selenium were more used for instance) but it seems to have changed. Package author and rOpenSci works and documentation did it.
After few tries with xpath spellings, I have found RSelenium pretty nice actually. I share here some recipes in this context: when you want to scrape a paginated table that is not purely HTML but a result of embedded javascript execution in browser.
A thing that wans’t particularly easy in Selenium at the beginning was how to extract sub-elements like html table code and not “source page as a whole”.
I have used innerHTML attribute for this.
This example explains how emulate clicks can be done to navigate from elements to others in the HTML page, and a more focus point on moving from page to page in a paginated table.
Here is a youtube video with subtitles I have made to illustrate it (no voice).
- First step to follow is to download a
selenium-server-xxx.jarfile here, see this vignette. - and run in the terminal :
java -jar selenium-server-standalone-xxx.jar - then you can inspect precisely elements of the HTML page code in browser and go back and forth between RStudio and the emulated browser (right click, inspect element)
- at the end use rvest to parse html tables
for instance find an id like league-chemp that we are using with RSelenium:
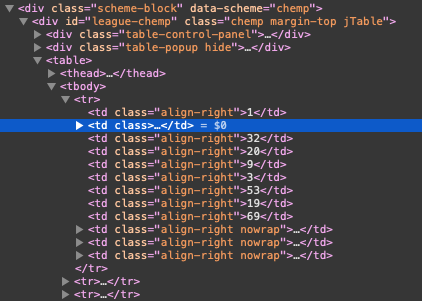
elem_chemp <- remDr$findElement(using="xpath", value="//*[@id='league-chemp']").
Here is a gist/snippets on github.
Also see the gist embedded below.
# https://stackoverflow.com/q/67021563/10527496
# java -jar selenium-server-standalone-3.9.1.jar
library(RSelenium)
library(tidyverse)
library(rvest)
library(httr)
remDr <- remoteDriver(
remoteServerAddr = "localhost",
port = 4444L, # change port according to terminal
browserName = "firefox"
)
remDr$open()
# remDr$getStatus()
remDr$navigate("https://understat.com/league/Ligue_1/")
# find championship table in html via xpath
elem_chemp <- remDr$findElement(using="xpath", value="//*[@id='league-chemp']")
# move to this table via script (optional)
remDr$executeScript("arguments[0].scrollIntoView(true);", args = list(elem_chemp))
# scrape the html table as a tibble
results_champ <- read_html(elem_chemp$getElementAttribute('innerHTML')[[1]]) %>%
html_table() %>% .[[1]] %>%
slice(-1)
# find player table in html via xpath
elem_player_page_number <- remDr$findElement(using="xpath", value="//*[@id='league-players']")
# find it using html id directly
# elem_player_page_number <- remDr$findElement(using="id", value = "league-players")
# find number of pages of this paginated table
player_page_number <- read_html(elem_player_page_number$getElementAttribute('innerHTML')[[1]]) %>%
html_nodes('li.page') %>%
html_attr('data-page') %>%
as.integer() %>%
max()
# move to this table via script
remDr$executeScript("arguments[0].scrollIntoView(true);", args = list(elem_player_page_number))
# or scroll at the bottom of page
# body_b <- remDr$findElement("css", "body")
# body_b$sendKeysToElement(list(key = "end"))
# then you can go to top
# body_b$sendKeysToElement(list(key = "home"))
i <- 4
one_table_at_a_time <- function(i){
# move on the desired page
elem_click <- remDr$findElement('xpath',
glue::glue('//*[@id="league-players"]
//*[normalize-space(@data-page) = "{i}"]'))
remDr$mouseMoveToLocation(webElement = elem_click)
elem_click$click()
# get the table for 10 players
elem_player <- remDr$findElement(using="xpath", value="//*[@id='league-players']")
results_player <- read_html(elem_player$getElementAttribute('innerHTML')[[1]]) %>%
html_table()
message('Player table scraped, page ', i)
results_player %>%
.[[1]] %>%
filter(!is.na(Apps)) %>%
return()
}
# one_table_at_a_time(3) %>% View
# loop over pages
resu <- 1:player_page_number %>% purrr::map_df(one_table_at_a_time)